Blog :: DLR Consultants
We have won an award!!!
DLR Consultants Proud to be Named a Top UK AI Development Firm by Clutch
Dom Roberts 30th January 2019

In light of our success and impact, we’ve been named one of the top UK technology experts by Clutch, a B2B ratings and reviews authority. We received the award for our outstanding work development work and we couldn’t be more excited.
We’d like to take this opportunity to thank all of our wonderful clients. They helped us achieve this award by participating in one on one client interviews on our behalf to gauge our impact on their operations. They ranked our service according to our cost, attention to project timelines, and overall quality. We’re happy to report that in reflection of their feedback, our Clutch profile has received a wonderful five out of five stars! Please take a look at a recent review from Oakleaf Software, one of our clients based out of Ware, Hertford
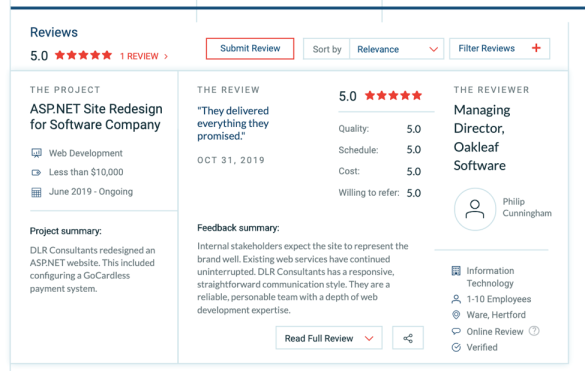
Clutch is a B2B market research firm that uses a unique ratings methodology to compare and contrast leaders across different sectors. We’ve also been recognized by their two sister sites, The Manifest and Visual Objects. The Manifest, a business data and how-to site, names us on their top list of UK AI companies. Visual Objects, a company portfolio resource, lists us on their top custom software developers in the United Kingdom. Thank you one and all for making this award possible! Please drop us a line if you’d like to collaborate on a project with DLR Consultants today.
On the development of Seeing Rooms
Dom Roberts 4th January 2019
The government special advisor Dominic Cummings has this week caused quite stir by putting out what appears to be a job advert, calling on people to join his development of special advisors and a development department aimed at transforming the UK government. The post which appears here at Mr Cummimngs' blog gives a lengthy description of not just the sort of people that he is looking to recruit, but also, some indications of what he is intending to do. It is an absolutely fascinating insight into what he considers the failings of the UK governemnt current structure. I have to agree with much of what he says and it is a very exciting oppotunity to really pull this country in to a world leading force through the integration of Technology and Government.
One area that I have found particularly fascinating is the concept of "Seeing Rooms", an idea that is grounded in the work by Bret Victor. But, what is a seeing room and secondly how do you develop such a system?
What is a Seeing Room?
There is a talk from Bret Victor here on Vimeo where he presents a talk on his concept of Seeing Spaces. The discussion concentrates on how can we build systems so that those who need to make decisions can have views on the information that they need in order to make accurate decisions based on teh latest information. This is not just an idea that is required for government, but. is something that anyone running a company of scale should be looking to have. Banks, Insurers, Power Companies etc need to have the full insight into the current scenario in real-time should they need to. It is also not just about what is going on right now, but to war-game situations that have not even occurred yet. A company or a governemnt need to be able to make decisions based on as much information as possible and also to see how they would respond and their environments would respond under different scenarios. Through a process of obtaining the data, augmenting it, simulating it, recording and playing it back a management team can run through not just the scenarios but review their own response to the situations under test, reset back to a position that they had control of and rework what failed, fine tuning their responses. However, this is not just about training, it is about reacting quickly with the maximum available information. In the modern boardroom, cabinet office, operating theatre or even theatre of war trying to make the most of spreadsheets, reports and reams of paper / documents just do not represent a reflection of what can be achieved through modern technology and continue to restrict decision makers to 2D, out of date information leading to ill-informed decisions.How do you build a Seeing Room?
The key points to any "Seeing Room" / "Control Room" architecture are- Streamable Data
- Data Layering
- Data Visualization
- Visualization Augmentation
- Human Interaction Simulation
This can be achieved by packaging the data streams into a consistent and yet extensible data format. Data formats such as NumPy's Array structures are flexible and can act as a starting point but they need to go further. Data is not just a matter of numbers, there is textual data, visual data, geo-location data and many others that will need to be integrated in to the system.
Streamable Data
In most situations, and I would imagine the UK government departments are the same, you can't just rock up there with the idea of building a "Seeing Room" and have all of their data available in lovely, Kafka Streaming data sources. Instead, what you get is a whole set of Excel Spreadsheets, a bunch of disparate REST APIs and systems that may just send out reports. So, how do you convert these in to Data Streams that can be reused, repurposed and integrated in to the facilities in the Room?Excel Spreadsheets
Spreadsheets are in abundance throughout most businesses, banling is terrible for them. But, they could be converted in to a dyanmic data source. Host the sheet in a Docker container, open the Spreadsheet using the Excel Interop and expose the cell data via generic API. There are two main directions for this, if the spreadsheet needs to be edited and worked on by multiple user simulataneously this can easily be done via the API. As many people as necessary could easily be permitted to view and update the data simultaneously as well as extracting any information in the data in to any visualization. Build the Spreadsheet in to a Docker container, connect the Interop API on startup and expose it through a Port on the container. The container will also contain a Redux caching layer that sits on top of the API to prevent split reads / writes during updates.REST APIs
REST APIs are useful and a big step in the right direction in comparison with Excel spreadsheets but how do you integrate all of the different APIs from a myriad of places in to one system? You can't go building out integration layers from every single system as they are required. The time it would take to build out bridges for each source and continue to do so every time a new one is brought online would be prohibitive. There are platforms already available to convert a REST API in to a stream, API Friends offer such a system, but, it is not that hard to build. Any API using Open API is readable and can be automatically attached to with dynamically generated data models, built out of the Swagger description. Then layer a cache on top of the API and poll it at a pre-determined frequency. When the responses change you update the cache and pump the repsonse on to the Stream. This converts the static API in to an Observable stream. Understanding the API is then a matter of configuration. The data structures are now automatically generated and the updates are observable and update automatically. By adding a configuration system that listens to the end of the Pipe and enriches it with meta data that describes the purpose of the data each stream can then be integrated in to the main system.
Data Visualization
The data visualizations should not be limited in anyway, different scenarios require different ways to view and understand data. A user should be able to gerenate their own visualisatons dynamically. There would be standard templates for views to initiate discussions. Data should then be allowed to be dragged from one display to another, stacked, merged and joined in unlimited ways. It is easy to see how a simple data table can then have a visualization dropped on to it and instantly convert it to a bar chart, but then by dropping another visualization on top of it the views are combined in to a different display. The user should be able to drag data around, expand the number of dimensions by moving more data on to the display and by linking the fields on the data view, pivot the data into another dimension and then view that with 3Dimensional views. At a recent client, we built something similar to this. We built visualizations as templates, any developer can then build a new template and add it to eh system and automatically a user can then select to view any data through that template. The project did not expand the system to allow for users to manipulate the data but that would have been an interesting addition to the project.It could be done by designing the templates in a two tiered system that you would expect to see in a presentation system such as MVVM or MVC, first the data would be converted into the View Model and then a secondary level is used to display. Layering the View Models prior to the presentation would permit the data to be repeatedly converted in any format before the final display.
Human Interaction Simulation
The ability to simulate the responses of humans to situations would be of incredible use to a vast array of situations and industries. From testing how people board planes, respond to layout changes in supermarkets to terror attacks, the possibliities are endless but this would clearly be a difficult things to achieve currently. It isn't a problem for the use of Machine Learning, certainly not Machine Learning alone. ML isn't really the implementation of Artificial Intelligence in the true sense. There is no Intelligence involved, it is in fact a matter of fine tuning a set of values within an algorithm to generate a result. The machine is trained against large amounts of data repeatedly until the netowrk of values converge to values that generate the correct result when evaluated against the non-test data. But ML is good at finding the result for a specifc task that it has been trained on, it is also not great a finding the result everytime it is more a case of achieving an 80-20 response, it is the Black Swan situations that ML struggles with. However, it is the Black Swan situations where the getting an accurate response is of the most importance.There is a lot of work in this field in Gaming for non-player characters but this does not go deep enough in to the problem to be fully applicable here, we would need to go much deeper, much more accuate. This is going to be an essential field over the next decade or so, work by David Cox and co at IBM describe this field as Neuro-Symbolic AI. A combination of Neural Nets and Cognitive AI to combine the ability of ML to recognise scenarios and cognitive AI to react logically to ML output. Combine this with Agent Based modelling to embed a mini-brain into each agent.
The agent would be defined with a set of attributes that can be adjusted to obtain differing responses to scenarios. This is similar to an application that I worked on many years ago for Simulating a football match for a computer game. We built a logic system where each player made a decision on each frame tick based on the circumstance on that frame. Start by generating the perfect response player and then tuning down the ability by adjusting the attributes.
A Wordpress site hack
Dom Roberts
9th November 2019
The first thing to do was to look at the site using Fiddler, this should give us an insight in to where the pages were being redirected to. Open Fiddler, switch on the traffic capturing and open the infected site in the Browser. The requests that the page is making should start being listed in the Fiddler UI. Look through the requests and see if there is anything there that looks unusual. In this case there was a request being made to https://withbestwishesjanny.com/follow and on inspecting the response I could see that it is a javascript segment that stops the page load and redirects the site elsewhere. This was clearly the offending script. To block it locally so that we can see the rest of the page add an Autoresponder in Fiddler to return some other response.
With the Autoresponder now activated you should be able to see the whole page load as normal. So, open it in Chrome and switch on the developer tools and the Network tab. Now, reload the page and look at the traffic again and we are looking for the script that you have blocked. When you find it it will show a link to where in the Javascript it was being called from. This should give the name of the file, which in this case is Pixel.js. Now go to the source of the page in Chrome Dev tools and look for any references to this pixel.js file. When you find it this should give you the script that you then need to remove from the page. If you have access to the SQL database for the site then you can run a SQL script to replace this text with an empty string and that should be that, hopefully.
Getting the most out of Docker
Dom Roberts
1st October 2019
It's a great new product to add to our burgeoning suite of Apps we have available
Call or contact now for a free, no obligation Consultation
Payment Gateway Pricing
We have been investigating the use of the different Payment gateways available for a Client of ours. There are so many different options available now that it is takes a bit of investigating to decide which of the different options is best suited to your needs. It is not a matter of one solution fits all. You have to look at how your business will be receiving their money, is it a monthly recurring fee, one of payment, payment through Credit Cards, Debit Cards etc. So many different combinations result in different fee levels.
Here is a rough breakdown of the main platforms and their fees.
PayPal
Charges 1.9% + £0.20 per transaction when transactions are between £1,500 and £55,000 per month. 2.9% + £0.20 per transaction when transactions are less than £1,500 per month.
Square
Charges 2.9% +£0.30 per transaction and 3.4% for recurring payments.
Stripe
Charges 1.4% for payments within Europe, 2.9% for Transaction outside of Europe.
Their documentation is very extensive and makes things much easier to set up the payment system to suit your needs.
World Pay
There are 2 payment plans
Pay As You Go: No monthly fees 2.75% per transaction
Monthly Subscription: £19.95 per month and 0.75% for Debit Cards 2.75% for Credit Cards.
These are the biggest systems in the world at the moment, even more popular than PayPal. Handles transactions in a huge number of currencies.
Sage Pay
Charges £20.90 per month fees plus 2.09% per transaction on Credit Card 0.74% on Debit Card.
You have to remember with all of these systems that you can either have a link through to their own widgets or payment gateways that take your user off of your site to their to make the payment, or you can develop an integrated system in to your own site using their APIs but that then requires developers. The additional benefit of using the APIs is that it can automate your backend systems as well. Using the companies own gateway systems will require someone to go in and consolidate that against your accounts each month. It is the choice of paying someone up front to build the software or the ongoing cost of the manually consolidating the payments.
At DLR Consultants we would be happy to talk you through these options and help to build out a bespoke software gateway for your business.
Call or contact now for a free, no obligation Consultation
After the Summit
The London AI Summit is over for another year. Really enjoyed it this year with some really interesting talks. Especially enjoyed the one from Fujitsu on the Annealing system that runs on a Quantum prepared system. They made a point of making it clear that this is a digital system and not based on Q-Bits.
Following from this had a great chat with IBM about their CPLEX optimizer. This is an area of great interest for us. Optimization Algorithms are an area that we really enjoy working in and any opportunity to discuss this fascinating subject is always of interest. Certainly a tool set that we will be looking to make more use of in the future.
Had a very interesting chat with Chris from The QuantFoundry, really interesting to talk to someone behind a start up in the same field as ourselves.
Now looking forward to next year's and can't wait to see what comes out of the new contacts we have made at the conference.
Call or contact now for a free, no obligation Consultation
London AI Summit
It was great to get down to the London AI Summit at Excel yesterday. Met up with lots of people from around the industry and it was great to see so much activity in the AI industry. The financial AI talks were great yesterday and am really looking forward to seeing the Quantum talks today.
There was an incredible amount of innovation on display as well as representation from the giants if the software industry. It all shows what a major disruptor the AI rebirth has been and how it truly is here to stay. We can only see the summit going from strength to strength over the coming years.
Call or contact now for a free, no obligation Consultation
Is Scrum Agile enough in a microservices world?
Micro-services are one of the key components of many modern system architectures. There are many benefits to keeping the scope of a service small, one of which is the ability to deliver updates in isolation. In a well designed system a service should represent a single, functional implementation rather than performing a multitude of purposes. The code base should be relatively small and ideally well tested. This makes it a great fit for a smooth CI/CD pipeline that can handle a short release cycle.
At one of our recent clients we spent some time adjusting the deployment process to get it to a point where merges in to Trunk could easily progress through to deployment whenever required. This is an important place to be when you have high turn over of features demanded by your customers. But, how does this sit with an iterative development process such as Scrum?
Scrum is great when you have a large project or a set of co-reliant services that are released on a regular schedule. The team determines the content of the release at the beginning of an iteration and then, ideally, delivers that at the end. The result being a new released package. In a fast moving micro-services landscape though releases can occur mid-sprint. Where does that fit in the Scrum process?
Well, there is nothing to say that it can't fit. One possibility is to state as part of the sprint goals is to deliver each component as many times as required.
An alternative approach though would be to use Kanban. Kanban requires you to keep the flow of work moving, there needn't be a start and end point to the cycles. Instead Kanban can take a section of work and move it through the process quickly. Team members are reassigned to different parts of the pipeline as bottle necks build to ensure that items flow smoothly from design through to Release. In this way your items can be released to production each time a viable product is complete. Design and development start when there is capacity in those channels, the team work on each step as required rather than over the course of the iteration.
When you move to a micro-services design maybe it's also time to rethink how agile you are and how agile you could be. Scrum has been a big part of development for well over a decade now and has been a benefit to millions of teams. It's not always the correct fit though. Maybe it's time that you looked to a different approach to maximise the productivity of your Dev teams.
Call or contact now for a free, no obligation Consultation
Add Application Insights without an Azure Account
Application Insights is a great tool for monitoring your applications. Out of the box it will send record Metrics about the incoming, outgoing traffic to your application, monitor the application state when running on the server, CPU Usage, Available memory in Bytes as well as standard Exception tracking. However, a general implementation requires that you have an Azure account in order to make any use of this data apart from when it is run under Visual Studio. That doesn't have to be the case though. We have worked with clients to add a simple system that will transfer the data to their ElasticSearch instance and a variety of other end points are available as well.
The starting point is to include the relevant Application Insights libraries to your application. Using NuGet import either the Microsoft.ApplicationInsights.Web and Microsoft.ApplicationInsights.WindowsServer assemblies to your project although it is feasible to have both set up if you need the Telemetry from both packages. The redirection of the Telemetry data is achieved through the use of an EventFlow Pipeline. You need to install a package for Microsoft.Diagnostics.EventFlow.Inputs.ApplicationInsight to bind to the Telemetry being exported from AppInsights and then add a output, in this case we are going to use Microsoft.Diagnostics.EventFlow.Outputs.ElasticSearch to send our data out to ES.
The pipeline to be created is a DiagnosticPipeline from Microsoft.Diagnostics.EventFlow which implements IDisposable thus allowing you to wrap the Run call (in the instance of a ASP.Net Core Web API service) in a using statement. The pipeline is created with the use of a sink and a HealthReporter. To create the HealthReporter we have used a CsvHealthReporter using the following,
var reporter = new CsvHealthReporter(new CsvHealthReporterConfiguration());
Then an insightItem can be created with
var insightItem = ApplicationInsightsInputFactory().CreateItem(null, reporter);
and an inputList with
var inputs = new[] { factory};
The sink is then constructed as an array
var sinks = new[] {
new EventSink(new ElasticSearchOutput(new ElasticSearchOutputConfiguration {
ServiceUri =
using(var pipeline = new DiagnosticPipeline(reporter, inputs, null, sinks, null, true))
{
You should now have configured AppInsights to generate the Telemetry as configured in your AppInsights configuration and have it sent through to your ES instance.
More work is required to then prevent the POST messages that are sent to ES from being listed repeatedly in the Telemetry as DependencyTelemetry calls, but I'll save that for another post.
Call or contact now for a free, no obligation Consultation
Tournament Selection in Genetic Algorithms
Genetic Algorithms are based on the Darwinian concept of survival of the fittest. Improving the fitness of a solution is achieved by breeding from the strongest genomes. Tournament Selection is a powerful way of implementing this. On each iteration of the algorithm multiple nodes are assigned to a tournament of a fixed number of competitors. After the scoring of the fitness function the competitors are compared and the winners are moved in to the next iteration.
There are many variants of how to handle the tournament, how many competitors to include, what to do with the losing participants etc. One way to avoid getting caught in local minima is to maintain some losing nodes into a further round or moving them into another tournament to cross polenate other segments of the batch. In tests, during the building of a GA for the N-Queens problem, varying sizes of tournament were tested. The initial implementation of a 2 member competition showed good improvement over no competition. However, a tournament size of 3 was able to more rapidly remove invalid combinations and hone in the correct sequences.
Tournament selection is a key tool in the armoury of a Genetic Algorithm developer. Each application of the GA varies in the way in which it should be approached. Testing the parameters and variations in the implementation is an important step in the development process.